This machine learning mind map is designed to make the field easier to scan. People often mix up ML tasks, methods, and application areas as if they were the same thing. They are not. A cleaner mental model is to separate three perspectives:
- what kind of task is being solved
- which methods are being used
- where the system is being applied
That is the purpose of this machine learning mind map.
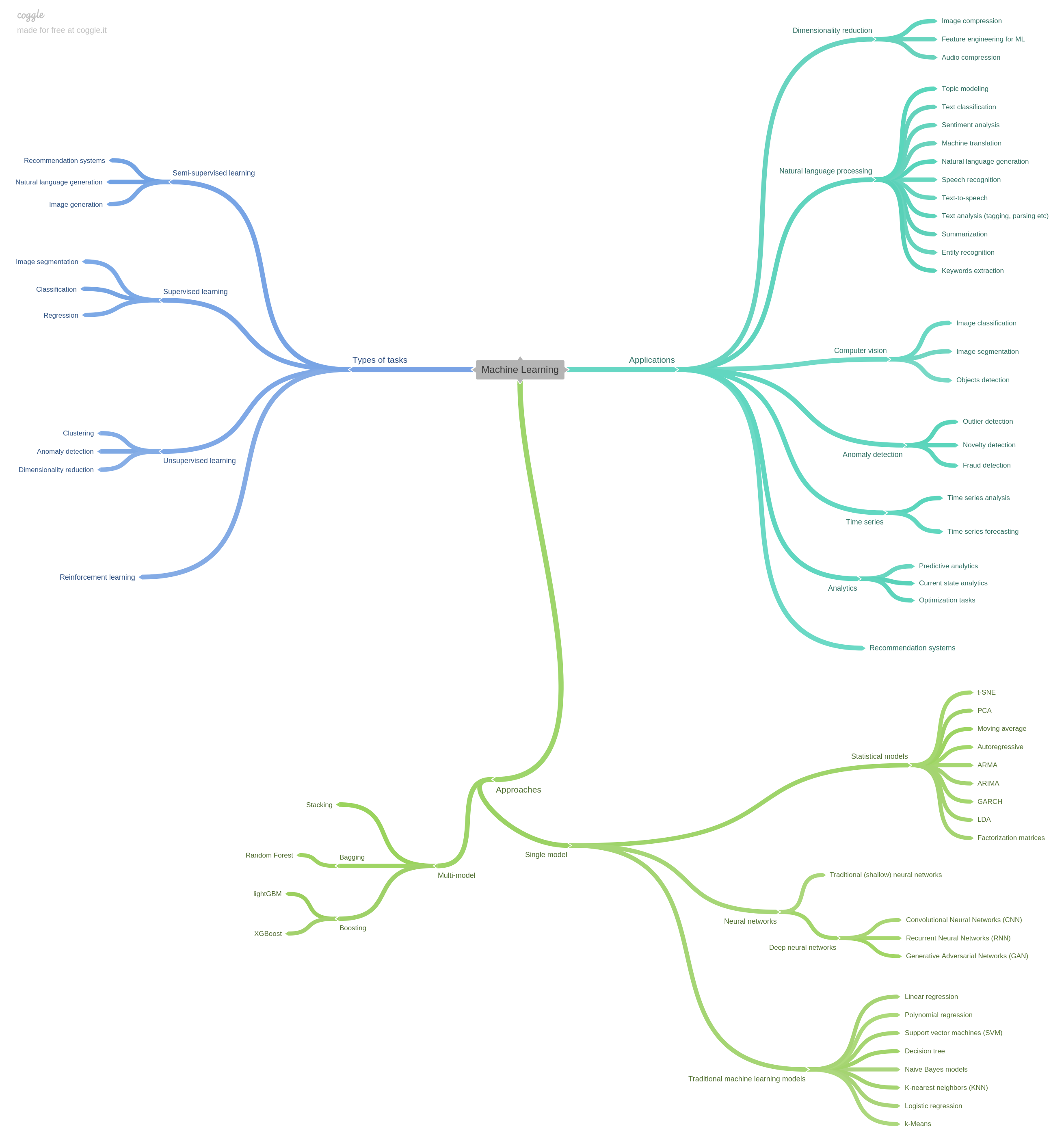
1. Types of tasks
The first useful distinction is the kind of learning problem:
- supervised learning
- unsupervised learning
- semi-supervised learning
- reinforcement learning
This matters because the choice of task type shapes everything else: data requirements, evaluation, labeling effort, and the kinds of models that are realistic.
Most commercial ML work still sits in supervised and weakly supervised settings, but the broader taxonomy helps explain why ML is not one monolithic technique.
2. Methods and model families
The second branch of the map is about how the task is being solved. This includes:
- classical statistical methods
- traditional ML models
- neural networks
- ensemble methods such as bagging, boosting, and stacking
This distinction matters because different model families have different tradeoffs around interpretability, data requirements, inference cost, and operational complexity.
A manager or technical lead does not need to memorize every algorithm, but they do need to understand that model choice should follow the problem rather than hype.
3. Application areas
The third perspective is where ML is being applied. Common application families include:
- natural language processing
- computer vision
- anomaly detection
- recommendation systems
- forecasting and time-series analysis
- optimization and decision support
This is the branch that people usually recognize first because it is closest to business outcomes. But it only makes sense when paired with the task and method branches above.
Why this framing still matters
The tools inside machine learning have changed a lot. The underlying structure has changed less.
Even now, it is still useful to ask:
- Is this a classification problem, a forecasting problem, or something else?
- Do we need a simple baseline or a more complex model family?
- Is the main challenge data quality, model choice, or deployment?
Those questions prevent teams from collapsing everything into the label “AI.”
What the mindmap leaves out
No map of ML is complete. A modern production view would also include:
- data quality and feature pipelines
- evaluation and validation
- deployment and monitoring
- feedback loops and retraining
- governance and human oversight
That said, the map still works as a strong conceptual starting point because it organizes the field in a way that helps people orient themselves.
Conclusion
The value of this mindmap is not that it captures every technique. Its value is that it separates machine learning into understandable layers: task types, methods, and application areas.
That framing makes ML easier to discuss, easier to scope, and easier to connect to real business problems. Once those categories are clear, the rest of the conversation becomes much more grounded.
Need Help Turning Machine Learning Ideas Into Production Systems?
ActiveWizards helps teams design practical machine learning, NLP, and computer vision systems that can move from prototype to production.