Data science is broad enough that non-technical leaders often struggle to build a stable mental model of it. That problem matters because managers still need to make decisions about hiring, prioritization, scope, vendors, infrastructure, and business value even if they are not writing models themselves.
This mindmap is meant to provide that operating overview.
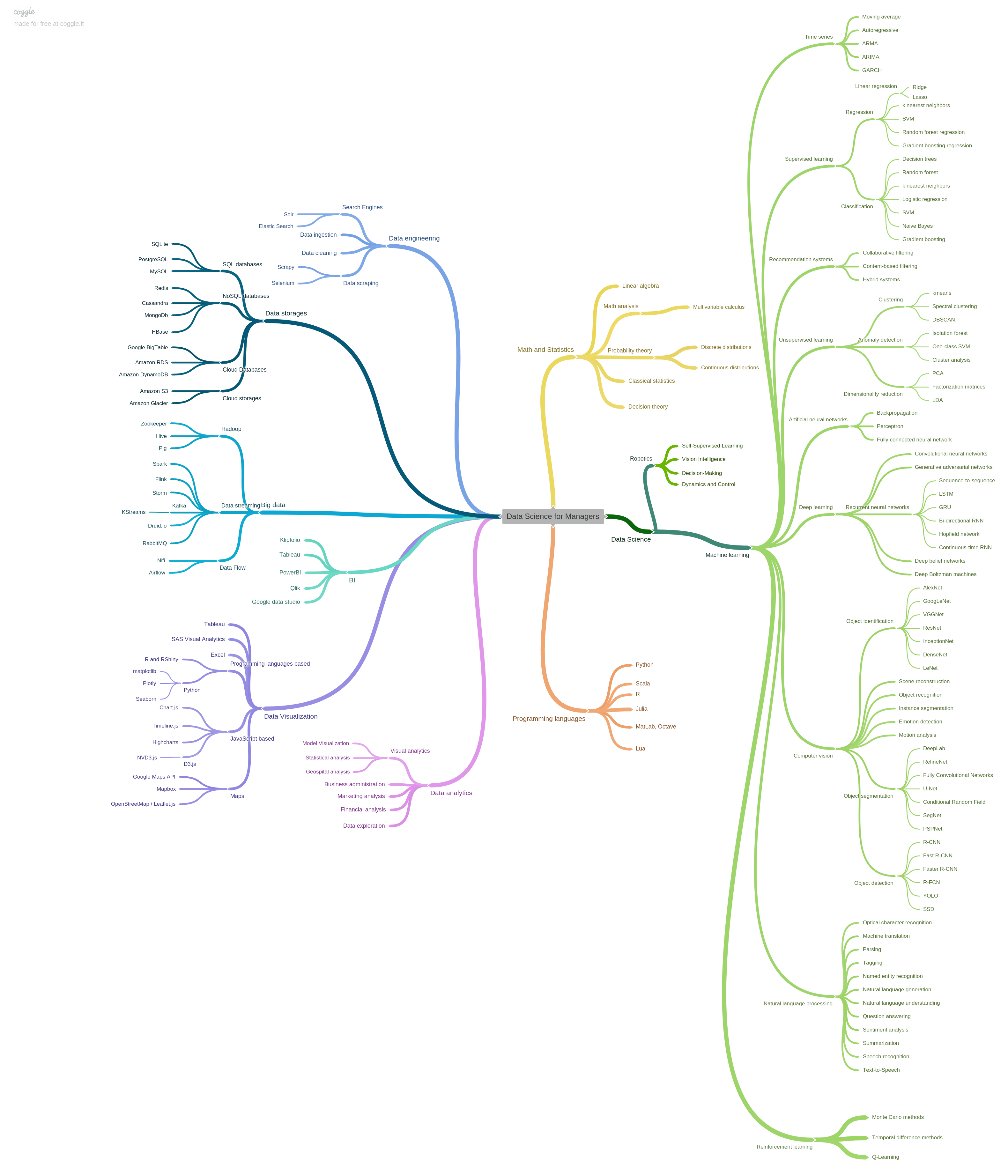
How managers should read the map
The point of the map is not to memorize every branch. It is to understand the main layers that shape a real data-science effort:
- mathematical and statistical foundations
- programming and implementation choices
- data engineering and storage
- analytics and business intelligence
- machine learning and automation
- domain-specific applications
In other words, data science is not only modeling. It is the combination of data preparation, analysis, decision support, and production execution.
The foundation layer
At the base of any serious data-science program are mathematics, statistics, and programming.
Managers do not need to derive equations or write production code, but they do need to understand:
- why data quality affects model quality
- why evaluation methods matter
- why language and tooling choices shape delivery speed
- why statistical confidence is different from business confidence
This foundation helps managers avoid treating ML as magic.
The data layer
Most projects fail earlier in the data layer than in the modeling layer. Storage, ingestion, transformation, quality checks, and access patterns determine whether the team can work effectively at all.
That is why the mindmap includes:
- data storage
- data engineering
- big data and pipeline concerns
- analytics and reporting
A manager who understands this will usually scope projects more realistically than one who jumps directly to algorithms.
The model layer
Machine learning, NLP, computer vision, recommendation systems, forecasting, and other applied ML areas sit on top of the data foundation. These branches are often the most visible, but they depend on all the earlier layers being strong enough to support them.
For managers, the practical question is not “Which algorithm is best?” It is “Which kind of problem are we solving, and what level of sophistication does it actually require?”
The delivery layer
The map also matters because data science is not finished when a model trains successfully. Managers need to think about:
- deployment
- monitoring
- feedback loops
- integration with operational workflows
- ownership across engineering, analytics, and business teams
This is where many initiatives stop being “interesting” and start becoming commercially useful.
What managers should take away
The most important takeaway is that data science is an operating system for decisions, not just a collection of algorithms.
Managers who understand the map can usually do three things better:
- ask clearer questions
- scope projects more realistically
- evaluate whether a team has the missing pieces needed for success
That is often more valuable than having shallow exposure to many technical buzzwords.
Conclusion
This mindmap remains useful because it gives managers a stable view of how data science fits together: foundations, data, models, and delivery. The exact tools will change over time. The structure of the work changes much less.
If you are leading a data initiative, the right next step is not learning every branch deeply. It is understanding how the branches depend on one another so you can make better decisions about where to invest next.
Need Help Turning Machine Learning Ideas Into Production Systems?
ActiveWizards helps teams design practical machine learning, NLP, and computer vision systems that can move from prototype to production.