A Practical Guide to Kafka Connect: Ingesting Data from Anywhere (Databases, Files, APIs)
A Practical Guide to Kafka Connect: Ingesting Data from Anywhere (Databases, Files, APIs)
Apache Kafka excels at moving vast amounts of data, but how do you get data *into* Kafka from your myriad existing systems? And how do you get it *out* to where it needs to go? Manually writing custom producers and consumers for every data source and sink is time-consuming, error-prone, and difficult to scale. This is where Apache Kafka Connect shines.
Kafka Connect is a robust framework included with Apache Kafka for reliably streaming data between Kafka and other systems like databases, file systems, cloud storage, search indexes, and SaaS applications. It provides a scalable, fault-tolerant way to build and manage data ingestion and egress pipelines with minimal custom coding.
At ActiveWizards, we've leveraged Kafka Connect in countless projects to solve complex data integration challenges. This practical guide will walk you through its core concepts, common use cases, and best practices, so you can effectively use Kafka Connect to ingest data from (almost) anywhere.
Why Kafka Connect? The Pain Points It Solves
Before diving into the "how," let's appreciate the "why." Kafka Connect addresses common data integration headaches:
- Boilerplate Code Reduction: No more writing repetitive producer/consumer logic for common data sources/sinks.
- Scalability & Fault Tolerance: Connect workers can run in a distributed cluster, automatically handling load balancing and failover for your connectors.
- Configuration over Code: Define data pipelines largely through JSON configurations.
- Schema Management Integration: Works seamlessly with Schema Registry for data validation and evolution.
- Offset Management: Automatically handles Kafka offsets for most source connectors, ensuring data isn't missed or duplicated.
- Rich Ecosystem: A vast number of pre-built connectors are available from Confluent, the community, and vendors.
Kafka Connect Core Concepts: The Building Blocks
Understanding these terms is key to working with Kafka Connect:

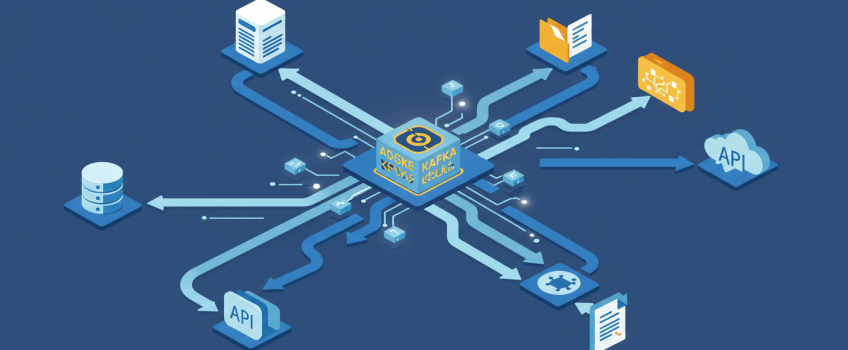
Diagram 1: Kafka Connect High-Level Architecture.
- Connectors:The high-level abstraction. You configure a connector instance to move data between a specific external system and Kafka. There are two types:
- Source Connectors: Ingest data from external systems *into* Kafka topics.
- Sink Connectors: Export data *from* Kafka topics to external systems.
- Tasks: Connectors delegate the actual data copying work to one or more tasks. A task is a lightweight thread of execution. Running multiple tasks for a connector allows for parallelism.
- Workers:These are the JVM processes that run the connectors and their tasks. Kafka Connect can run in two modes:
- Standalone Mode: A single worker process runs all connectors and tasks. Useful for development, testing, or very small-scale deployments. Configuration is in local files.
- Distributed Mode (Recommended for Production): Multiple workers form a cluster. Connectors and tasks are distributed and balanced across these workers by Kafka Connect itself, providing scalability and fault tolerance. Configuration is managed via a REST API.
Kafka Connect: Standalone vs. Distributed Mode
| Feature | Standalone Mode | Distributed Mode |
|---|---|---|
| Primary Use Case | Development, testing, small single-node tasks. | Production, scalability, fault tolerance. |
| Scalability | Limited to a single worker process. | Horizontally scalable by adding more workers to the cluster. |
| Fault Tolerance | None; if the worker fails, all connectors/tasks stop. | High; if a worker fails, its tasks are rebalanced to other workers. |
| Configuration Management | Via local properties files. | Via a centralized REST API. Connector configs stored in Kafka topics. |
| Offset Management | Offsets typically stored in a local file. | Offsets stored centrally in Kafka topics, providing fault tolerance. |
- Converters: Responsible for converting data between Kafka Connect's internal data format and the format required by the external system or Kafka. For example, converting JSON from a file into Avro for Kafka, or vice-versa. Common converters include those for Avro, JSON Schema, JSON, String, and Bytes.
- Transforms (Single Message Transforms - SMTs): Allow you to make simple, stateless modifications to individual messages as they pass through Kafka Connect, without writing custom code. Examples: adding a field, renaming a field, casting a type, routing messages to different topics based on content.
- Offset Management: Source connectors typically track the "offsets" or progress they've made in the source system (e.g., a database timestamp, a file offset) and store this information in Kafka topics to resume correctly after restarts.
Pro-Tip on Converters: For production systems handling structured data, always prefer schema-enforced converters like AvroConverter or ProtobufConverter along with a Schema Registry. This prevents data quality issues and makes schema evolution manageable.
Practical Use Cases & Configuration Examples
Let's explore how to use Kafka Connect for common ingestion tasks. For these examples, we'll assume you're using Kafka Connect in **Distributed Mode** and interacting with its REST API (e.g., using `curl`). The JSON configurations below can be saved to files (e.g., jdbc_source_config.json) and used with `curl --data @jdbc_source_config.json`.
Use Case 1: Ingesting Data from a Relational Database (e.g., PostgreSQL)
Problem: You want to capture changes from your `products` table in PostgreSQL and stream them into a Kafka topic named `product_updates` for real-time analytics or microservice consumption.
Solution: Use a JDBC Source Connector (e.g., Confluent's JDBC Connector or Debezium for Change Data Capture - CDC).

Diagram 2: PostgreSQL to Kafka via JDBC Connector.
Example Configuration (Conceptual - Confluent JDBC Source Connector for bulk/timestamp mode):
{
"name": "jdbc-postgres-product-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url": "jdbc:postgresql://your_postgres_host:5432/your_database",
"connection.user": "your_user",
"connection.password": "your_password",
"topic.prefix": "pg_",
"table.whitelist": "public.products",
"mode": "timestamp+incrementing",
"timestamp.column.name": "updated_at",
"incrementing.column.name": "id",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://your_schema_registry_host:8081"
}
}
Key Configuration Points:
connector.class: Specifies the connector plugin to use.connection.url,.user,.password: Database connection details.table.whitelist: Which tables to pull from.mode: How to detect new data (e.g., `timestamp`, `incrementing`, `timestamp+incrementing`). For full CDC, Debezium is preferred.timestamp.column.name: The column Kafka Connect watches for new/updated rows.value.converter&schema.registry.url: Using Avro with Schema Registry is a best practice for structured data.
Pro-Tip for Databases: For true Change Data Capture (CDC – capturing inserts, updates, and deletes as they happen), explore connectors like Debezium. It reads the database's transaction log, providing a more robust and complete stream of changes compared to timestamp/incrementing polling.
Use Case 2: Streaming Log Files into Kafka
Problem: Your application servers generate important log files, and you want to stream these logs into Kafka for centralized analysis, monitoring, or alerting.
Solution: Use a File Source Connector (e.g., Confluent SpoolDir Connector, FilePulse Connector by StreamThoughts, or even a simple FileStreamSourceConnector for basic needs).

Diagram 3: Log Files to Kafka via File Connector.
Example Configuration (Conceptual - FileStreamSourceConnector for simplicity):
{
"name": "filestream-log-source",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max": "1",
"topic": "application_logs",
"file": "/var/log/myapp/application.log",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Key Configuration Points:
file: The specific file to tail. More advanced connectors (like SpoolDir or FilePulse) can monitor directories for new files.topic: The Kafka topic to send log lines to.
Pro-Tip: For production log ingestion, dedicated log shippers like Fluentd, Logstash, or Filebeat are often used to send logs to Kafka, offering more features like parsing, enrichment, and resilient shipping. However, Kafka Connect file connectors can be useful for simpler scenarios or specific file types.
Use Case 3: Ingesting Data from a REST API
Problem: You need to periodically pull data from an external SaaS application's REST API (e.g., fetching new customer sign-ups from a CRM) and stream it into Kafka.
Solution: Use an HTTP Source Connector (e.g., Kafka Connect HTTP by Landoop/Lenses.io, or other community connectors).

Diagram 4: REST API to Kafka via HTTP Connector.
Example Configuration (Conceptual - Highly dependent on the specific connector):**
{
"name": "http-crm-customer-source",
"config": {
"connector.class": "com.lensesio.kcql.connect.http.HttpSourceConnector",
"tasks.max": "1",
"connect.http.url": "https://api.mycrm.com/v1/new_customers",
"connect.http.method": "GET",
"connect.http.headers": "Authorization: Bearer YOUR_API_KEY",
"connect.http. χρόνος_απόκρισης_μετά": "PT5M",
"connect.http.kcql": "INSERT INTO crm_new_customers SELECT * FROM /json_path_to_customer_array",
"topic": "crm_new_customers",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}
}
Key Configuration Points (will vary greatly by connector):
connect.http.url: The API endpoint.connect.http.method: GET, POST, etc.connect.http.headers: For authentication tokens.- Polling interval and logic for fetching only new data (often requires custom logic or specific connector features like handling pagination or `since_id` parameters).
- Mapping the API response (often JSON) to Kafka records (KCQL is a common way with Lenses.io connector).
Pro-Tip: Ingesting from APIs can be complex due to rate limiting, pagination, authentication, and varied response structures. Thoroughly evaluate HTTP connectors for their ability to handle these aspects for your specific API. Sometimes, a small custom application (e.g., Python script using `requests` and `kafka-python`) might be more flexible for very custom API interactions.
Quick Reference: Kafka Connect REST API Endpoints (Distributed Mode)
Base URL: http://your_connect_worker_host:8083
GET /connectors: List active connectors.
POST /connectors (with JSON body): Create a new connector.
GET /connectors/{connectorName}: Get info about a specific connector.
GET /connectors/{connectorName}/status: Get current status of a connector and its tasks.
PUT /connectors/{connectorName}/config (with JSON body): Update a connector's config.
PUT /connectors/{connectorName}/pause: Pause a connector and its tasks.
PUT /connectors/{connectorName}/resume: Resume a paused connector.
POST /connectors/{connectorName}/restart: Restart a connector (often reloads tasks).
DELETE /connectors/{connectorName}: Delete a connector.
Running Kafka Connect & Deploying Connectors
- Start Kafka Connect Workers:In Distributed Mode, you start multiple worker processes. Each worker needs a properties file specifying its `bootstrap.servers` (Kafka brokers), `group.id` (for the Connect cluster), offset storage topics, converters, and the REST API listener address.
# Example command to start a worker (paths may vary) ./bin/connect-distributed.sh ./etc/kafka/connect-distributed.properties - Install Connector Plugins: Download the JAR files for your desired connectors (e.g., JDBC, File, HTTP) and place them in the `plugin.path` directory specified in your worker properties. Restart workers for them to pick up new plugins.
- Deploy a Connector Configuration:Using `curl` or another HTTP client, POST your JSON connector configuration (like the examples above) to the Kafka Connect REST API (typically running on port 8083 on your workers).
curl -X POST -H "Content-Type: application/json" --data @your_connector_config.json http://your_connect_worker_host:8083/connectors - Monitor and Manage:Use the REST API to check connector status, pause/resume connectors, view task status, and delete connectors.
# Get status of all connectors curl http://your_connect_worker_host:8083/connectors # Get status of a specific connector curl http://your_connect_worker_host:8083/connectors/jdbc-postgres-product-source/status
Best Practices & Deployment Checklist for Kafka Connect:
- Run in Distributed Mode for Production: Ensures scalability and fault tolerance.
- Use a Schema Registry: Crucial for evolving structured data from sources like databases (e.g., use AvroConverter).
- Monitor Your Connect Cluster: Track worker health, connector/task status (especially failures), lag, and error rates using JMX, REST API, or tools like Confluent Control Center.
- Allocate Sufficient Resources: Ensure Connect workers have adequate CPU, memory, and network bandwidth.
- Secure Your Connect Cluster: Implement SSL/TLS for all communication, secure the REST API, and manage connector credentials safely.
- Understand Connector-Specific Configurations: Deeply read the documentation for each connector you use.
- Idempotent Sink Connectors: If possible, configure sink connectors to be idempotent to handle message reprocessing gracefully.
- Error Handling & Dead Letter Queues (DLQs): Configure how connectors handle problematic messages (e.g., send to a DLQ topic instead of failing tasks).
- Manage Connector Plugins Carefully: Keep your
plugin.pathorganized and restart workers after adding/updating plugins. - Test Thoroughly: Validate connector configurations, data transformations, and error handling in a staging environment before production.
- Use Single Message Transforms (SMTs) Judiciously: Ideal for simple, stateless operations. For complex logic, consider a dedicated stream processor.
Conclusion: Simplify Your Data Integration with Kafka Connect
Apache Kafka Connect is a powerful and indispensable tool in the Kafka ecosystem. It dramatically simplifies the process of building and managing resilient data pipelines between Kafka and a multitude of other systems. By understanding its core concepts and leveraging its rich connector ecosystem, you can significantly reduce development effort and focus on deriving value from your streaming data, rather than just moving it.
While Kafka Connect handles many common scenarios, complex transformations, or integrations with highly proprietary systems might still require custom development. However, for a vast range of data ingestion and egress tasks, Kafka Connect provides an elegant and robust solution.
Further Exploration & Official Resources
To learn more about Kafka Connect and specific connectors:
- Apache Kafka Connect Official Documentation
- Confluent Kafka Connect Documentation (Includes many popular connectors)
- Confluent Hub - A marketplace for Kafka connectors. Search for specific connectors like "Debezium," "Kafka Connect HTTP," "FilePulse Connector" for their respective documentation.
Need to integrate diverse data sources with Apache Kafka?
ActiveWizards offers expert Kafka Connect consulting and development services. We can help you select, configure, and deploy the right connectors, or build custom solutions to meet your unique data integration needs.



Comments (0)
Add a new comment: